HEAP uses technology to unlock new insights into the exposome
The HEAP Data Life-Cycle
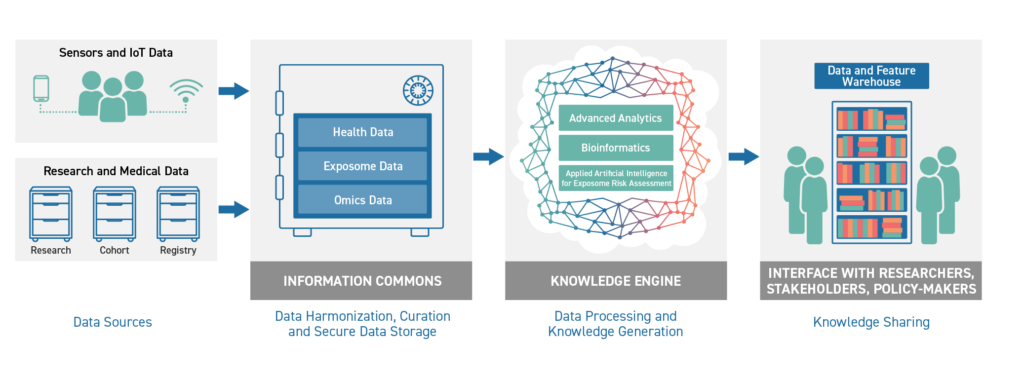
STEPS EXPLAINED
Step 1:
The HEAP Platform as a Service (PaaS) will harmonize and curate data, and stream it on demand to the HEAP Information Commons. The Information Commons consists of physical resources for storage and archiving, and interfaces for analysis and research. Its architecture is similar to that of a bank vault with safety deposit boxes.
Step 2:
Once the data are in the Information Commons, HEAP’s Knowledge Engine performs scientific analysis using bioinformatics pipelines. It also applies machine learning and deep learning to analyse, mine, produce, and validate hypotheses to produce actionable knowledge.
Step 3:
This knowledge will become part of the Data and Feature Warehouse and will be available for sharing.CONCEPTS EXPLAINED
Platform as a Service (PaaS):
The HEAP Platform as a Service (PaaS) makes complex data easy to access. It combines different data analytics platforms in a user-friendly environment. The PaaS, provided by Hopsworks, has a metadata designer that standardizes data and makes the data interoperable.
Knowledge Engine:
This is an engine that processes data in the Information Commons to produce actionable knowledge. The Knowledge Engine uses tools including bioinformatics and applied artificial intelligence.
Data and Feature Warehouse:
This is a central vault for storing documented, curated, and access-controlled features, enabling data scientists to easily access and discover features used to train machine learning.